
Apache Kafka is a robust distributed data platform developed by the Apache Software Foundation, proficient in processing streaming data in real time. Written in Java and Scala, Kafka is a favored choice for constructing real-time data streaming pipelines, especially for enterprise-level and mission-critical applications. Its high performance in data pipelines, streaming analytics, and data integration makes it indispensable for modern distributed applications that demand scalability to handle massive volumes of streamed events.
This tutorial will guide you through the installation of Apache Kafka on an Ubuntu 22.04 server, detailing manual installation from binary packages, basic configuration, and operations utilizing Apache Kafka.
Prerequisites
Before proceeding with the installation, ensure you have the following:
- An Ubuntu 22.04 server with a minimum of 2GB to 4GB of memory.
- A non-root user with sudo privileges.
Installing Java OpenJDK
Apache Kafka is built in Java and Scala, making it necessary to have Java OpenJDK installed on your system. At the time of this writing, Kafka version 3.2 requires Java OpenJDK version 11, available in the Ubuntu repository. Start by updating the Ubuntu repository:
sudo apt update
Proceed to install Java OpenJDK 11. Confirm the installation when prompted:
sudo apt install default-jdk
Once installation is complete, verify the Java installation:
java -version

Installing Apache Kafka
With Java OpenJDK set up, proceed to install Apache Kafka manually from binary packages. The following steps create a new system user and download the Kafka binary package:
sudo useradd -r -d /opt/kafka -s /usr/sbin/nologin kafka
Download the Apache Kafka binary package:
sudo curl -fsSLo kafka.tgz https://dlcdn.apache.org/kafka/3.2.0/kafka_2.13-3.2.0.tgz
Extract and move the package to the appropriate directory:
tar -xzf kafka.tgz sudo mv kafka_2.13-3.2.0 /opt/kafka
Adjust ownership for the Kafka installation directory:
sudo chown -R kafka:kafka /opt/kafka
Create a directory for Kafka logs and update the configuration file accordingly:
sudo -u kafka mkdir -p /opt/kafka/logs sudo -u kafka nano /opt/kafka/config/server.properties
# logs configuration for Apache Kafka log.dirs=/opt/kafka/logs
Setting Up Apache Kafka as a Service
To run Apache Kafka efficiently, set it up as a systemd service:
Create a systemd service for Zookeeper:
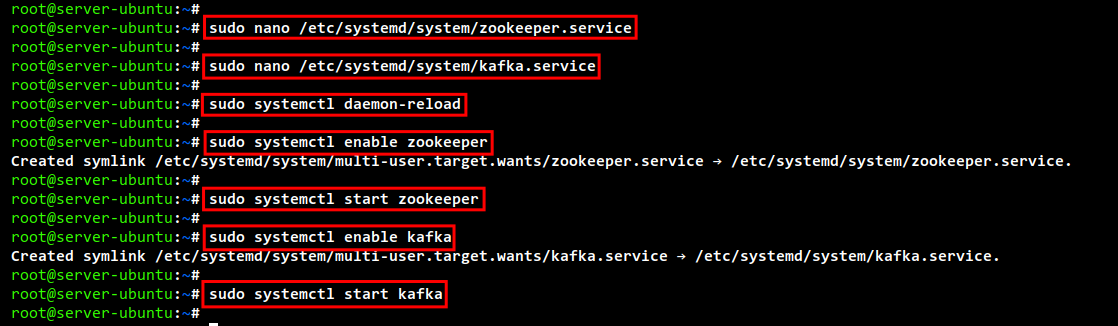
sudo nano /etc/systemd/system/zookeeper.service
[Unit] Requires=network.target remote-fs.target After=network.target remote-fs.target [Service] Type=simple User=kafka ExecStart=/opt/kafka/bin/zookeeper-server-start.sh /opt/kafka/config/zookeeper.properties ExecStop=/opt/kafka/bin/zookeeper-server-stop.sh Restart=on-abnormal [Install] WantedBy=multi-user.target
Create a service for Apache Kafka:
sudo nano /etc/systemd/system/kafka.service
[Unit] Requires=zookeeper.service After=zookeeper.service [Service] Type=simple User=kafka ExecStart=/bin/sh -c '/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties > /opt/kafka/logs/start-kafka.log 2>&1' ExecStop=/opt/kafka/bin/kafka-server-stop.sh Restart=on-abnormal [Install] WantedBy=multi-user.target
Apply the new systemd services:
sudo systemctl daemon-reload
Enable and start the Zookeeper and Apache Kafka services:
sudo systemctl enable zookeeper sudo systemctl start zookeeper
sudo systemctl enable kafka sudo systemctl start kafka
Check the status of these services:
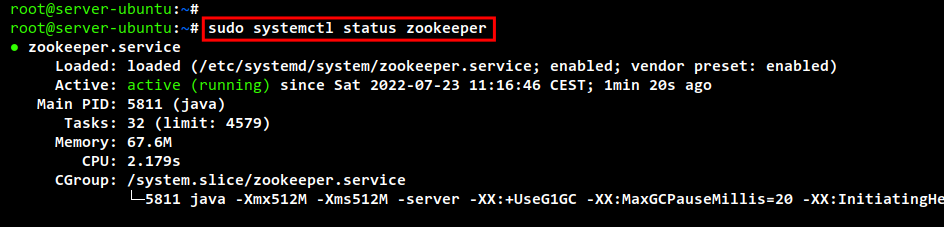
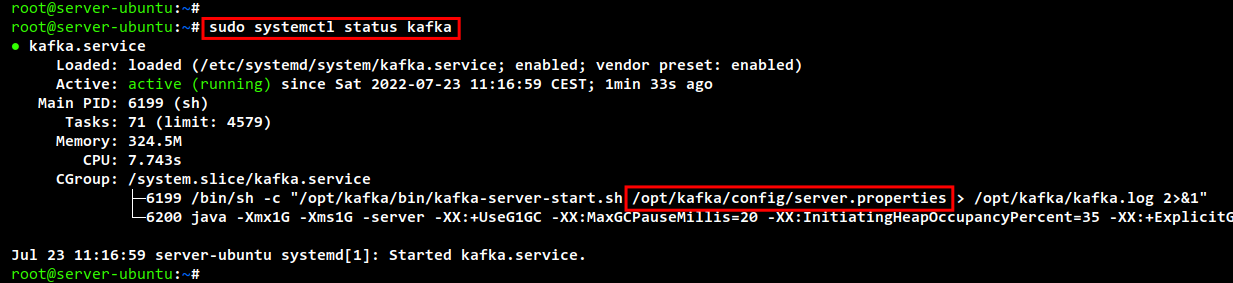
sudo systemctl status zookeeper sudo systemctl status kafka
Basic Apache Kafka Operations
With the installation complete, you can perform basic operations using Kafka’s command-line tools located in /opt/kafka/bin:
Create a Kafka topic:
sudo -u kafka /opt/kafka/bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic TestTopic
List available topics:
sudo -u kafka /opt/kafka/bin/kafka-topics.sh --list --bootstrap-server localhost:9092

Write and stream data using Kafka Console Producer and Consumer:
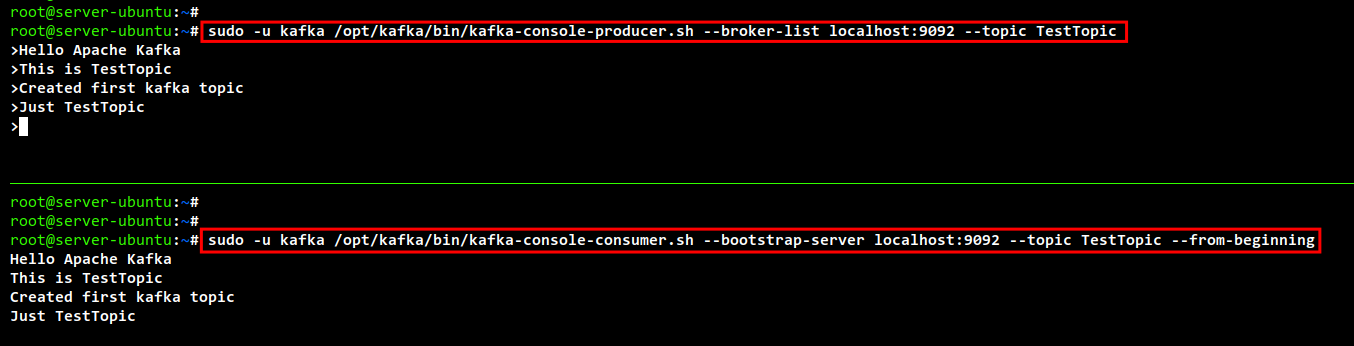
sudo -u kafka /opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic TestTopic
In a separate terminal, start the Kafka Consumer:
sudo -u kafka /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic TestTopic --from-beginning
To delete a topic:
sudo -u kafka /opt/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic TestTopic
Streaming Data from Files Using Kafka Connect
Kafka allows data streaming from files using the Kafka Connect plugin, included with the default installation:
Modify the configuration file for Kafka Connect:
sudo -u kafka nano /opt/kafka/config/connect-standalone.properties
plugin.path=libs/connect-file-3.2.0.jar
Create and populate a file to stream:
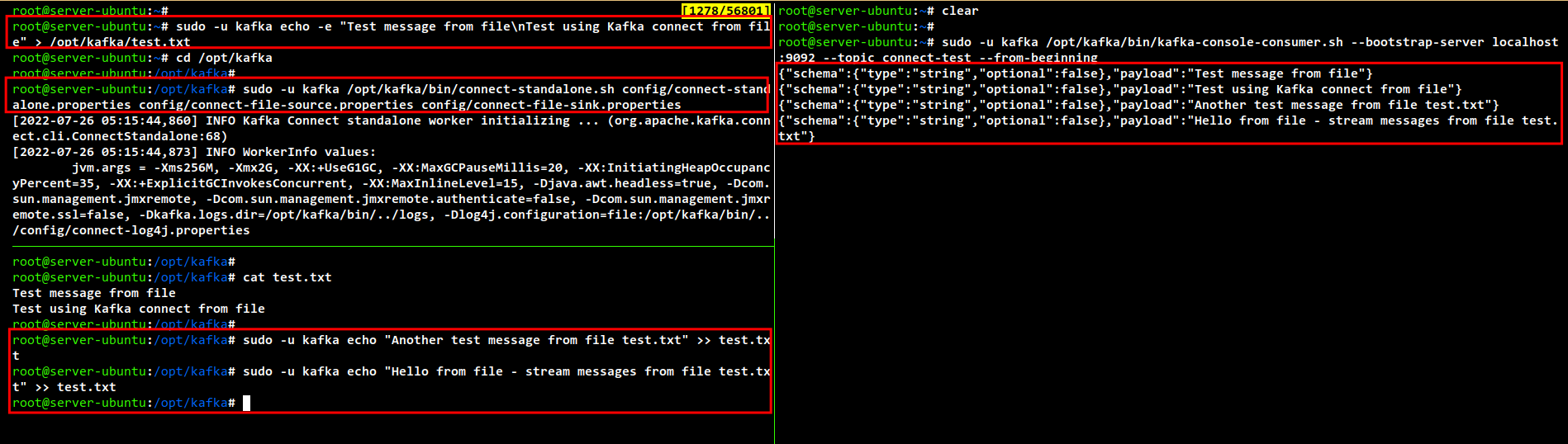
sudo -u kafka echo -e "Test message from file\nTest using Kafka connect from file" > /opt/kafka/test.txt
Start the Kafka connector in standalone mode to handle file-based streaming:
cd /opt/kafka sudo -u kafka /opt/kafka/bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
In a separate terminal, consume the streamed data:
sudo -u kafka /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic connect-test --from-beginning
Append new data to the file and observe how it streams through Kafka:
sudo -u kafka echo "Another test message from file test.txt" >> test.txt
Conclusion
Congratulations on learning how to install Apache Kafka on an Ubuntu 22.04 system! This tutorial covered installation, configuration, and basic operations with Kafka Producer and Consumer, as well as file-based streaming using Kafka Connect. These skills will allow you to build and manage efficient data streaming pipelines and applications.
FAQ
What is Apache Kafka?
Apache Kafka is a distributed data store optimized for real-time processing and high-performance data streaming tasks, widely used in many industries for building streaming data pipelines and applications.
What is the role of Zookeeper in Kafka?
Apache Zookeeper is critical for managing and coordinating Kafka brokers in a cluster, handling tasks like configuration management, synchronization, and providing group services.
Can I install Apache Kafka on a different version of Ubuntu?
Yes, while this tutorial is designed for Ubuntu 22.04, you can generally adapt it for other versions or distributions. Ensure you check compatibility with Java versions and available package repositories.
How do I ensure data is streamed reliably?
For reliable data streaming, configure proper replication factors, and partitions, and monitor the Kafka brokers and Zookeeper for potential issues using tools designed for Kafka management and monitoring.