
Apache Spark is a versatile, open-source, distributed computational framework designed to deliver faster processing speeds. It supports various APIs, including Java, Python, Scala, and R, making it ideal for streaming and graph processing applications. While Apache Spark is often used within Hadoop clusters, it is also capable of running in standalone mode.
In this comprehensive guide, we will walk you through the steps to install the Apache Spark framework on a Debian 11 system.
Prerequisites
- A server running Debian 11.
- A root password configured on the server.
Installing Java
As Apache Spark is developed in Java, having Java installed on your system is crucial. If Java is not yet installed, you can do so using the following command:
apt-get install default-jdk curl -y
After the installation, verify the Java installation by running:
java --version
You should see output similar to the following:
openjdk 11.0.12 2021-07-20 OpenJDK Runtime Environment (build 11.0.12+7-post-Debian-2) OpenJDK 64-Bit Server VM (build 11.0.12+7-post-Debian-2, mixed mode, sharing)
Installing Apache Spark
As of this writing, the latest version of Apache Spark is 3.1.2. Download it with this command:
wget https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
After downloading, extract the file with:
tar -xvzf spark-3.1.2-bin-hadoop3.2.tgz
Then move the extracted directory to /opt:
mv spark-3.1.2-bin-hadoop3.2/ /opt/spark
Next, edit the ~/.bashrc file to add the Spark path variable:
nano ~/.bashrc
Insert the following lines:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Save and close the file, then activate the Spark environment variable:
source ~/.bashrc
Starting Apache Spark
Start the Spark master service with the command:
start-master.sh
You should see an output similar to:
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-debian11.out
Apache Spark listens on port 8080 by default. Verify this with:
ss -tunelp | grep 8080
The expected output is:
tcp LISTEN 0 1 *:8080 *:* users:(("java",pid=24356,fd=296)) ino:47523 sk:b cgroup:/user.slice/user-0.slice/session-1.scope v6only:0 <->
Now, start the Apache Spark worker process:
start-slave.sh spark://your-server-ip:7077
Accessing the Apache Spark Web UI
Access the Apache Spark web interface at http://your-server-ip:8080. You should see the master and worker services on the screen below:
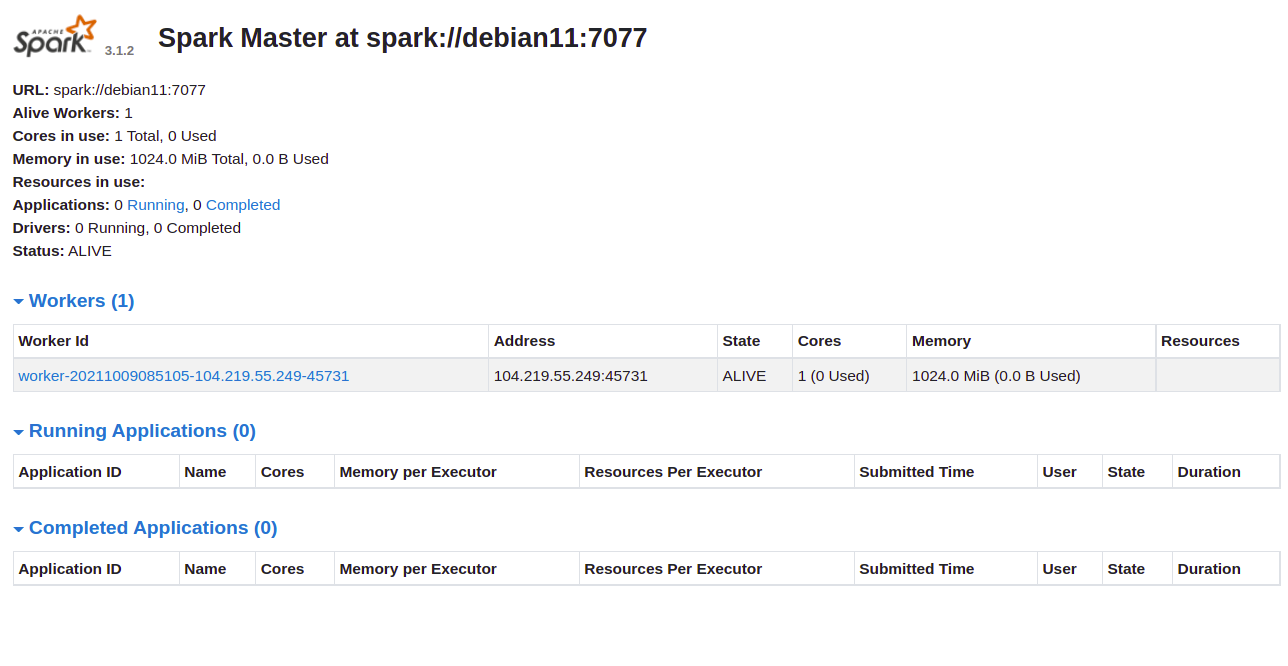
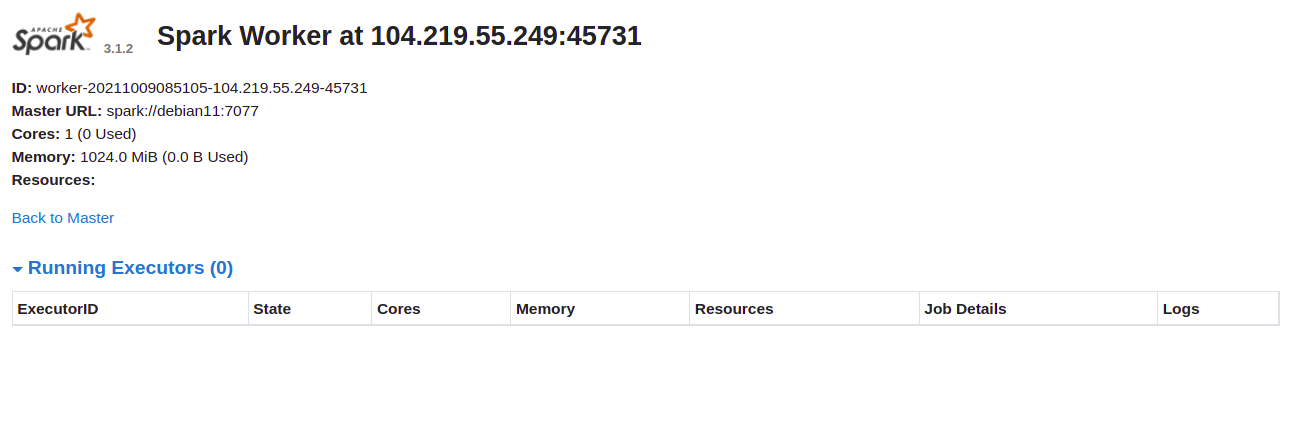
Click the Worker ID to view details on the subsequent screen:
Connecting to Apache Spark via Command-line
To connect to Spark using its command shell, use:
spark-shell
This connects you to an interface as shown:
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.12)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
To use Python with Spark, first install Python:
apt-get install python -y
Then connect to Spark with:
pyspark
You’ll see an interface like this:
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Python version 3.9.2 (default, Feb 28 2021 17:03:44)
Spark context Web UI available at http://debian11:4040
Spark context available as 'sc' (master = local[*], app id = local-1633769632964).
SparkSession available as 'spark'.
>>>
Stopping Master and Slave
Stop the slave process with this command:
stop-slave.sh
The output will be:
stopping org.apache.spark.deploy.worker.Worker
And stop the master process using:
stop-master.sh
The expected output is:
stopping org.apache.spark.deploy.master.Master
Conclusion
Congratulations on successfully installing Apache Spark on Debian 11! You’re now equipped to leverage Apache Spark for large-scale data processing within your organization.
Frequently Asked Questions (FAQ)
What is Apache Spark?
Apache Spark is a powerful open-source analytics engine for large-scale data processing with built-in modules for streaming, SQL, machine learning, and graph processing.
Do I need to uninstall Java if I have an older version?
It is generally recommended to update to the latest version of Java compatible with your applications for security and performance improvements.
Can Apache Spark run on Windows or macOS?
Yes, Apache Spark is cross-platform and can run on Windows, macOS, and Linux environments.
How can I verify that Spark is working?
After installation, you can verify Spark is working by accessing its web UI at http://your-server-ip:8080 and ensuring that the master and worker nodes are running.
Why would I choose standalone mode over a Hadoop cluster?
Running Apache Spark in standalone mode is simpler for development and testing or for use cases that don’t require the distributed computing capabilities of a large Hadoop cluster.