
Apache Spark is a robust open-source framework designed for general-purpose cluster computing. It offers high-level APIs in Java, Scala, Python, and R to support various execution graphs. With built-in modules for streaming, SQL, machine learning, and graph processing, Spark efficiently analyzes large datasets, distributing them across clusters for parallel processing.
In this guide, we will walk you through installing the Apache Spark cluster computing stack on Ubuntu 20.04.
Prerequisites
- A server running Ubuntu 20.04.
- Root access to the server.
Getting Started
First, ensure all system packages are up-to-date. Execute the following command:
apt-get update -y
Once the packages are updated, proceed to the next steps.
Install Java
Apache Spark requires Java to function. Install it using the following command:
apt-get install default-jdk -y
Verify the Java installation with:
java --version
You should see output similar to:
openjdk 11.0.8 2020-07-14 OpenJDK Runtime Environment (build 11.0.8+10-post-Ubuntu-0ubuntu120.04) OpenJDK 64-Bit Server VM (build 11.0.8+10-post-Ubuntu-0ubuntu120.04, mixed mode, sharing)
Install Scala
Since Spark is developed using Scala, install it with:
apt-get install scala -y
To confirm Scala’s version, use:
scala -version
You should see the following:
Scala code runner version 2.11.12 -- Copyright 2002-2017, LAMP/EPFL
Install Apache Spark
Download the latest Spark version from its official website. As of this writing, version 2.4.6 is the latest. Use:
cd /opt wget https://archive.apache.org/dist/spark/spark-2.4.6/spark-2.4.6-bin-hadoop2.7.tgz
Extract the downloaded file:
tar -xvzf spark-2.4.6-bin-hadoop2.7.tgz
Rename the directory for convenience:
mv spark-2.4.6-bin-hadoop2.7 spark
Configure Spark Environment
Edit the .bashrc file to configure the Spark environment:
nano ~/.bashrc
Append the following lines:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Save and close the file, then activate the environment:
source ~/.bashrc
Start Spark Master Server
With Spark installed, start the master server:
start-master.sh
This command will output something similar to:
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-ubuntu2004.out
Spark listens on port 8080 by default. Confirm using:
ss -tpln | grep 8080
Expected output:
LISTEN 0 1 *:8080 *:* users:(("java",pid=4930,fd=249))
Access the Spark web interface at http://your-server-ip:8080:
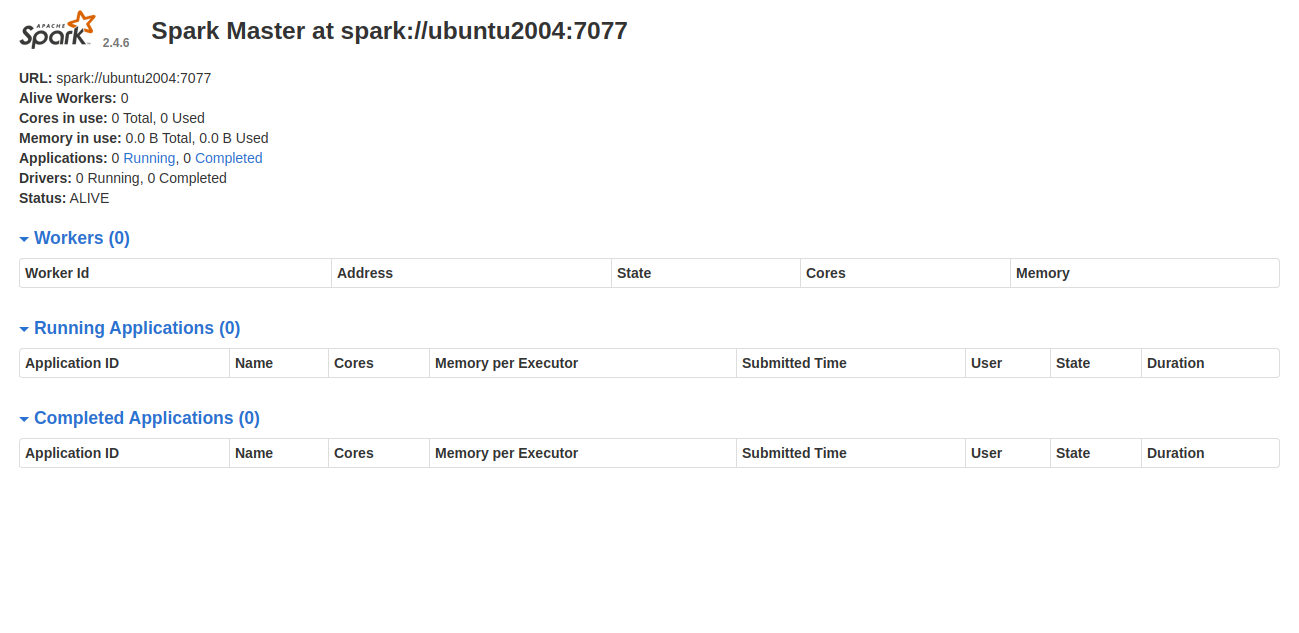
Start Spark Worker Process
Use the Spark master URL to initiate the worker process:
start-slave.sh spark://your-server-ip:7077
Expected startup message:
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-ubuntu2004.out
Refresh the Spark dashboard to see the worker process:
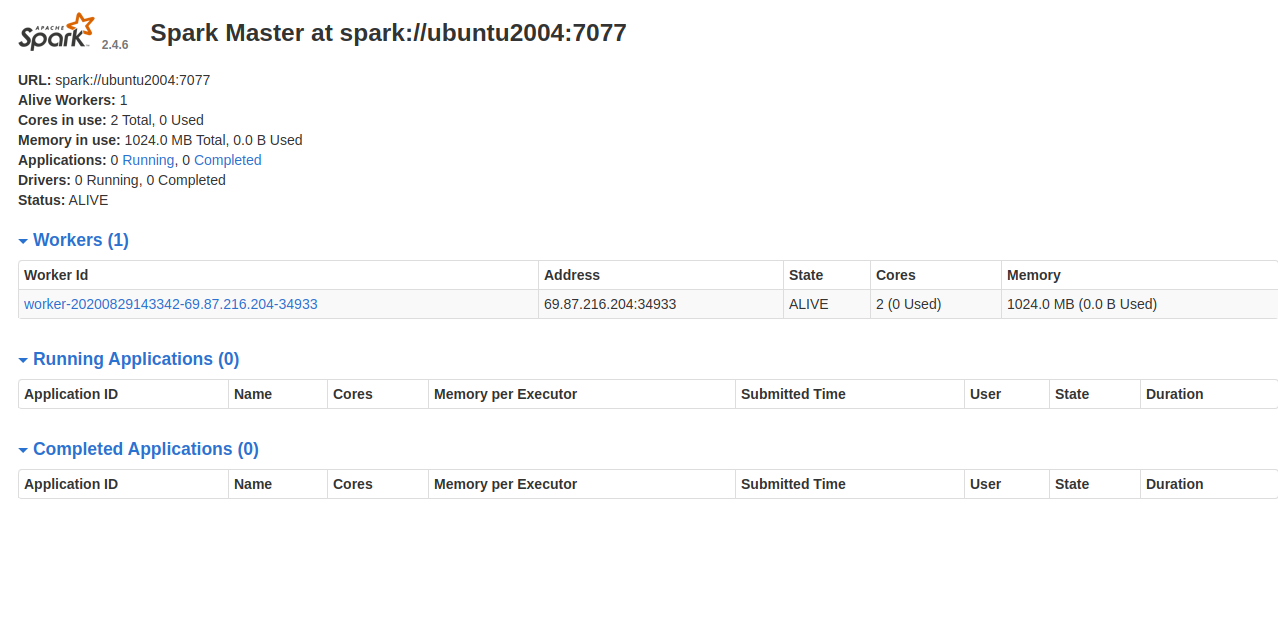
Working with Spark Shell
Connect to the Spark server using the command line:
spark-shell
Upon connection, you’ll see output like:
... Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://ubuntu2004:4040 Spark context available as 'sc' (master = local[*], app id = local-1598711719335). Spark session available as 'spark'. ...
Using Python with Spark
To use Python, install it with:
apt-get install python -y
Connect Spark with Python:
pyspark
You’ll see similar output:
... Using Python version 2.7.18rc1 (default, Apr 7 2020 12:05:55) SparkSession available as 'spark'. >>>
Stopping Spark Services
To stop both Master and Worker services, use:
stop-slave.sh stop-master.sh
Conclusion
Congratulations on your successful installation of Apache Spark on Ubuntu 20.04. You’re now set to perform basic tests or start configuring a Spark cluster. Feel free to reach out with any questions.
Frequently Asked Questions (FAQ)
What are the key components required for installing Apache Spark?
You need a Linux system (Ubuntu 20.04 in this guide), Java, and Scala to run Spark. Remember to set appropriate environment variables for Spark.
What is the default port for Apache Spark’s web interface?
Spark’s web interface is accessible via port 8080.
Can I use Python with Apache Spark?
Yes, you can use the PySpark command-line utility to interact with Spark using Python.
How do I stop Spark services?
Use the commands stop-slave.sh and stop-master.sh to halt the worker and master services, respectively.